Свертка
Слой Conv2d — это двухмерная свертка.
nn.Conv2d(in_channels,out_channels, kernel_size, stride, padding)
Изображение в оттенках серого состоит из массива шириной x пикселов и высотой y пикселов. Цветное RGB-изображение будет состоять из 3-х таких массивов. Количество входдных каналов — in_channels.
Фильтр, или ядро свертки,еще одна матрица, обычно меньшего размера, которую перетаскивают по изображению. Количеству фильтров out_channels — это число выходных каналов. По сути, количество низкоуровневых функций, которые, по мнению разработчика, могут указывать на целевой класс.
По сути, in_channels и ut_channels это количество входов и выходов сверточного слоя, но на каждый такой вход или выход приходится не одно число, а соответствующая матрица значений.
kernel_size — описывает высоту и ширину фильтра.Это или отдельный скаляр, задающий квадрат, или кортеж для прямоугольного фильтра.
Проводится умножендие каждого элемента в матрице на соответствующий член в другой матрице и результат складывается. Затем фильтр перемещается и процесс повторяется.
stride показывает, на сколько шагов по всем входным данным мы продвигаемся, когда настраиваем фильтр на новую позицию. Можно продвигаться с шагом 1, что дает карту признаков того же размера, что и ввода. Можно передать кортеж (a, b), что позволило бы перемещать a поперек и b вниз на каждом шаге.
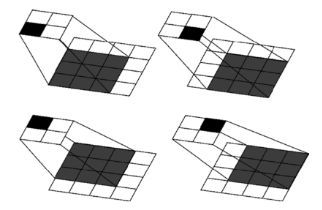
На рисунке ядро 3х3 с изображением 4х4 и шагом 1.
padding (отступ) – добавляется указанное количество строк и солбцов с нулями.
Если не задавать отступ, любые пограничные случаи, с которыми столкнется PyTorch в последних столбцах ввода, просто отбрасываются. Как и в случае с stride и kernel_size, можно передать кортеж для отступа height × weight, а не отдельное число, которое заполняется одинаково в обоих направлениях.
O = (W – K + 2*P) / S + 1
P = (K — 1) / 2
где O = выходной размер (output size),
W = выходной размер (input height or width),
K = размер ядра (kernel size),
P = отступ (padding),
S =шаг (stride).
Если параметры для высоты и ширины разные, то расчет по этой формуле проводится дважды.
Пулинг
Слои пулинга (субдискретизации) используются в сочетании со слоями свертки. Эти слои снижают разрешение сети от предыдущего входного слоя, что дает меньше параметров на нижних слоях. Такое сжатие приводит к более быстрым вычислениям вначале и помогает предотвратить переобучение сети.
nn.MaxPool2d(kernel_size=3, stride=2)
Целью пулинг слоя является уменьшение размера, но не глубины карты объектов, сгенерированной предыдущей сверткой. Другими словами, для цветного изображения пулинг слой сохраняет информацию RGB, но сжимает пространственную информацию. Это делается для того, чтобы позволить ядрам выборочно фокусироваться на определенных нелинейных функциях. Это уменьшает вычислительную нагрузку, позволяя сосредоточиться на параметрах, которые оказывают наибольшее влияние. Наличие меньшего количества параметров также уменьшает тенденцию к чрезмерной подгонке.
Пулинг слои очень похожи на обычные слои свертки в том смысле, что они используют матрицу ядра, или фильтр, для выборки изображения. Разница с объединением слоев заключается в том, что объединение уменьшает выборку входных данных.
Ядро сдвигаясь на шаг выделяет тензоры во входном поле, аналогично движению ядра по изображению в свертке. MaxPool берет максимальное значение каждого из этих тензоров. Как и в слоях свертки, в Max Pool есть опция дополнительных гиперпараметров для управления степенью дополнения входного тензора данных нулями (padding), которая создает границу нулевых значений вокруг тензора в случае, если шаг выходит за пределы окна тензора.
Распространенным методом является получение среднего значения тензора, которое позволяет всем тензорным данным вносить вклад в субдискретизацию, а не задействовать только одно значение в случае с max.
Кроме того, в PyTorch есть слои AdaptiveMaxPool и AdaptiveAvgPool, которые работают независимо от размеров входящего тензора.
Рекомендуется использовать их в модельных архитектурах поверх стандартных слоев MaxPool или AvgPool, поскольку они позволяют создавать архитектуры, которые могут работать с различными входными измерениями; это удобно при работе с несопоставимыми наборами данных.
Прореживание
nn.Dropout()
Слой Dropout — не будет обучаться случайный набор узлов сети во время цикла обучения. Поскольку они не будут обновляться, у них не будет возможности соответствовать исходным данным, и поскольку они случайные, каждый цикл обучения будет игнорировать различный выбор входных данных, что должно способствовать обобщению еще больше.
Dropout(p=0.2) 0.2 входного тензора обнуляется случайным образом. По умолчанию p=0.5.
Dropout должен происходить только во время обучения! Если бы он происходил во время предсказания, сеть бы поглупела. Реализация Dropout в PyTorch определяет режим работы, и передает все данные через слой Dropout во время вывода
Sequentia
nn.Sequential() позволяет создавать цепочку слоев по логическому принципу. Данные последовательно проходят через каждый элемент массива слоев.
Например, сверточная нейронная сеть может быть разбита на две цепочки: блок features (все сверточные слои) и блок classifier.
Или в отдельне nn.Sequential() могут включаться только наборы слоев для свертки – Свертка, Пулинг, Функция активации.
Литература
- Deep Learning with PyTorch. Quick Start Guide // David Julian
- Пойнтер Ян Программируем с PyTorch: Создание приложений глубокого обучения. — СПб.: Питер, 2020. — 256 с.: ил.